Amazon Bedrock Knowledge Base와 Amazon S3 Vectors를 활용한 비용 효율적인 RAG 애플리케이션 구축 가이드
소개
RAG(Retrieval Augmented Generation)은 대규모 데이터에서 정보를 추출하여 생성형 AI의 응답 품질을 향상시키는 방법으로, 최근 많은 기업들이 도입하고 있는 기술입니다. 하지만 기존의 벡터 데이터베이스 환경은 고성능 SSD 스토리지나 인메모리 방식을 기반으로 하여 높은 비용을 수반하는 경우가 많아 대규모 지식 베이스를 구축할 때 제약이 있습니다. 이번 포스팅에서는 이러한 문제를 해결하기 위한 AWS 기반의 솔루션인 Amazon Bedrock Knowledge Bases와 Amazon S3 Vectors 통합 기능에 대해 소개하고, 자동화된 구축 가이드를 통해 어떻게 RAG 애플리케이션을 비용 효율적으로 배포할 수 있는지를 다룹니다.
본론
Amazon S3 Vectors는 클라우드 객체 스토리지 최초로 벡터 저장 및 조회 기능을 네이티브하게 제공하며, Amazon Bedrock Knowledge Bases와의 통합을 통해 고비용 벡터 데이터베이스의 대안으로 등장했습니다. 최대 90%의 비용 절감 효과와 초당 수백만 수준의 문서를 처리할 수 있는 확장성을 제공합니다.
활용 사례: 대용량 아카이브 데이터, 시맨틱 검색 자동화, 멀티미디어 데이터 처리 등 고비용 데이터베이스를 대체할 수 있는 다양한 환경에서 활용될 수 있습니다.
Amazon Bedrock 콘솔을 이용한 배포 가이드
- 새로운 Knowledge Base 생성
먼저 AWS Console에서 Bedrock > Knowledge Bases로 접속한 뒤 “Knowledge Base with vector store” 옵션을 선택합니다. Amazon S3를 벡터 저장소로 설정하고 IAM 역할을 설정합니다.

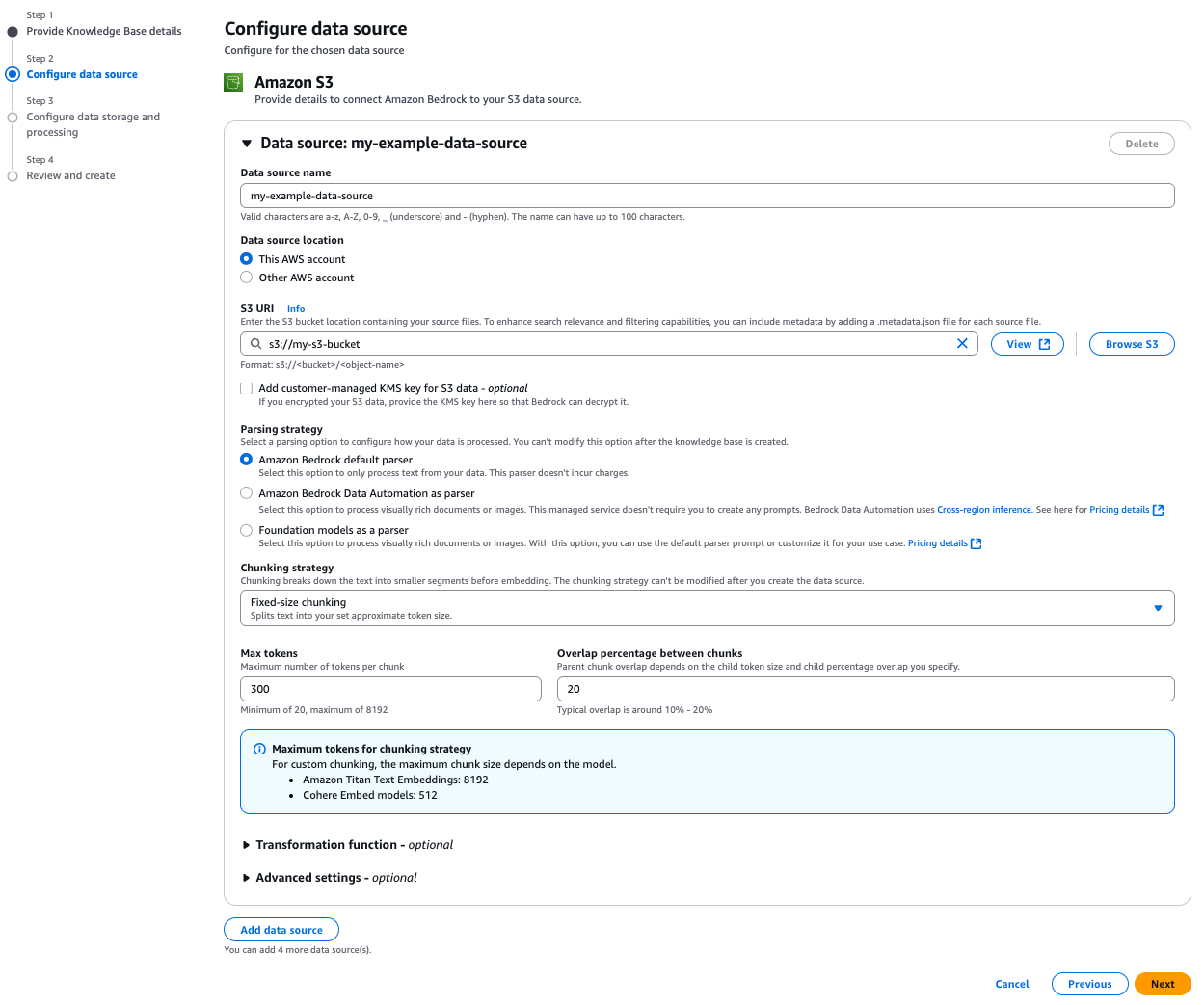
- 데이터 소스 설정
문서가 저장된 S3 버킷의 위치와 파싱 방식을 설정합니다. 텍스트 중심 문서의 경우 기본 파서를 사용하며, 복잡한 구조의 경우 Foundation Model 기반 파서를 선택할 수 있습니다.
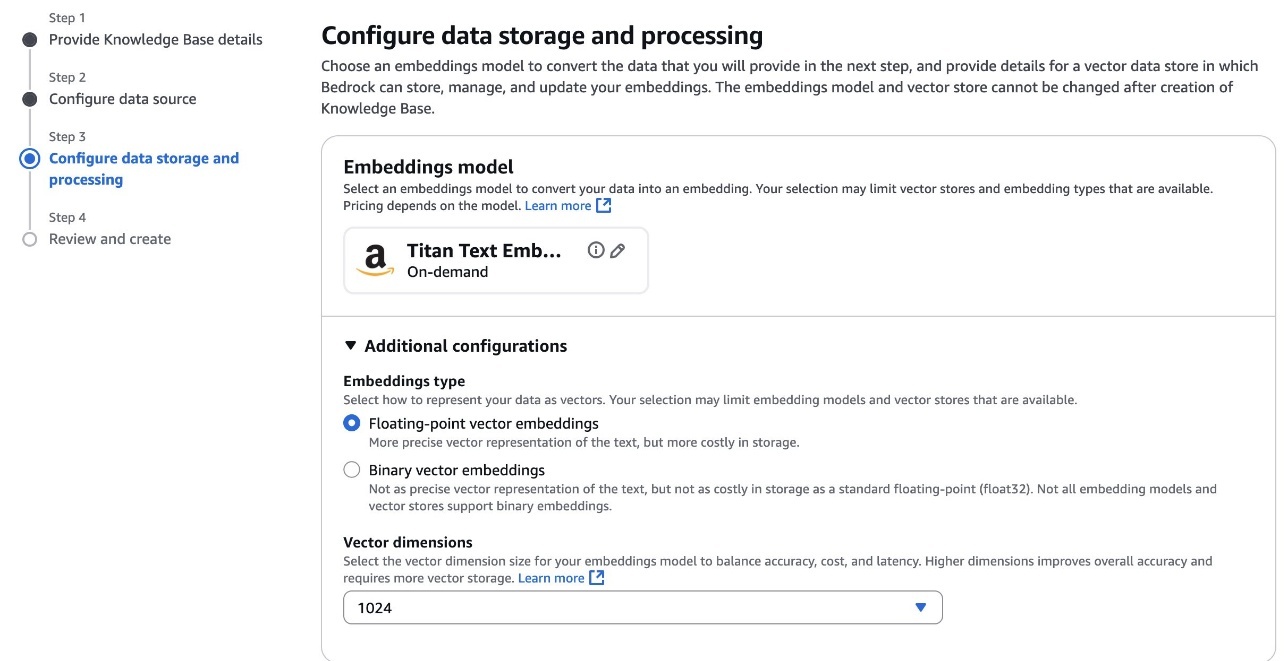
- 데이터 전처리 및 임베딩 설정
임베딩 모델(Amazon Titan 등)을 선택하고 벡터 임베딩을 위한 고정 사이즈 청크 방식, 암호화 설정 등을 진행합니다.
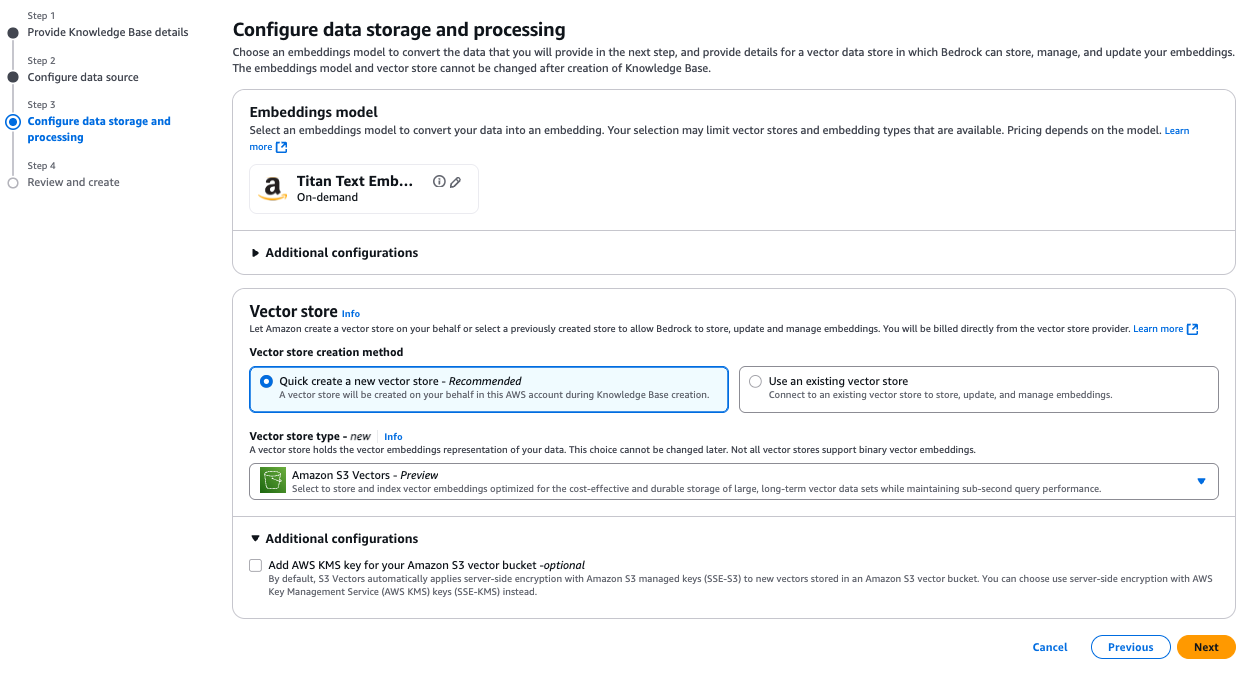
- S3 Vector 인덱스 구성
자동 생성(Quick Create) 또는 기존 인덱스를 연결하는 방식이 있으며, 후자의 경우 메타데이터 필터링 설정을 JSON으로 지정할 수 있습니다.
- 데이터 소스 동기화
Knowledge Base 설정이 완료되면 ‘Sync’를 클릭하여, 문서에서 벡터를 생성하고 지정한 S3 벡터 인덱스에 데이터를 업로드합니다.

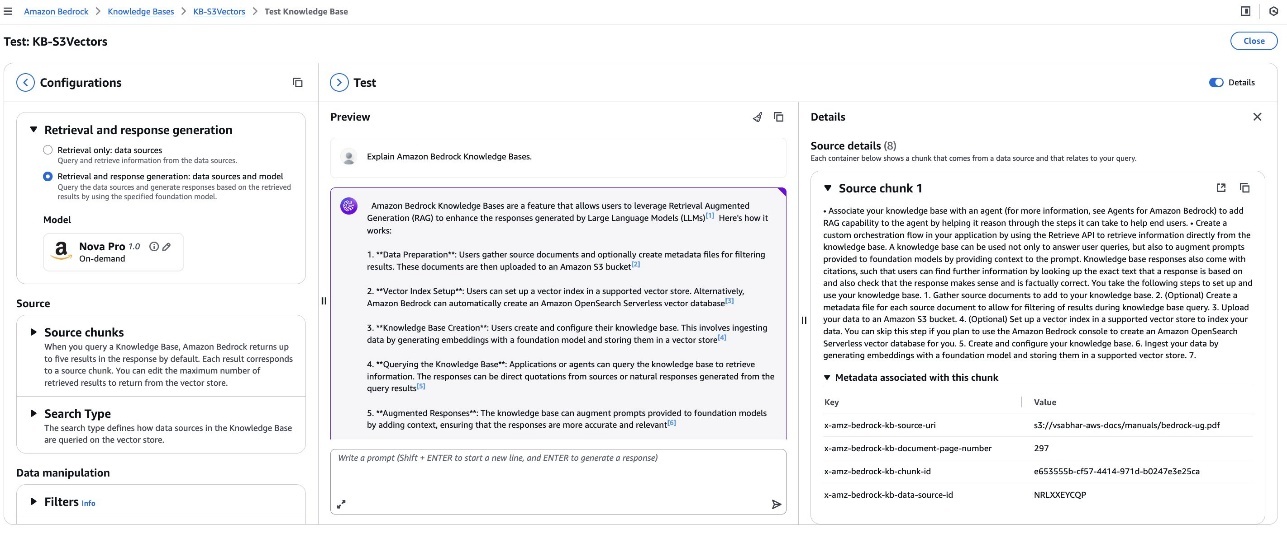
- 쿼리 테스트 및 검증
Retrieve Mode 또는 Generate 모드로 질의를 수행하고, 회수된 문서 청크와 생성된 응답 결과를 콘솔에서 직접 확인할 수 있습니다.
자동화 및 코드 기반 배포
AWS SDK를 사용하면 Knowledge Base의 생성을 Python 소스코드 기반으로 자동화할 수 있으며, S3 Vector 인덱스 정보와 IAM Role 등을 지정하여 인프라 관리를 자동화할 수 있습니다. 이 방식은 DevOps 파이프라인과 통합하여 CI/CD 환경을 쉽게 구현할 수 있습니다. 클린업 작업 역시 CLI 명령어를 통해 자동화된 방식으로 삭제할 수 있습니다.
결론
Amazon Bedrock Knowledge Bases와 Amazon S3 Vectors의 통합은 대규모 RAG 애플리케이션의 구축과 운영을 보다 합리적인 비용으로 가능하게 합니다. 특히 RAG 시스템 구축 시 자동화 및 확장성, 그리고 파인튜닝된 검색 품질을 동시에 갖춘 아키텍처를 원하는 조직에 매우 적합합니다. 메타데이터 필터링, 벡터 스토리지 최적화, 파서 및 청크 전략의 선택 등 설계 단계부터 세부 옵션을 최적화함으로써, 높은 수준의 활용성과 검색 성능을 기대할 수 있습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
