아마존 OpenSearch Service 샤딩 전략 가이드: 최적의 샤드 수 설정 방법
OpenSearch를 처음 사용하는 많은 사용자들이 가지는 공통적인 질문 중 하나는 “인덱스에 샤드를 몇 개 두는 것이 적절할까?”입니다. OpenSearch에서 인덱스는 하나 이상의 샤드로 구성되며, 이 샤드 수가 인덱싱과 검색 요청 처리 효율성에 직접적인 영향을 미칩니다. 본 포스팅에서는 OpenSearch Service에서 활용 가능한 샤딩 전략과 자동화 설정 방법, 다양한 워크로드에 따른 샤드 수 설정 가이드라인을 제공하고자 합니다.
샤드란 무엇인가?
OpenSearch를 포함한 검색 엔진은 기본적으로 두 가지 역할을 합니다. 문서셋으로부터 인덱스를 생성하고, 해당 인덱스를 사용하여 검색 질의를 계산하는 것입니다. 데이터가 적으면 인덱스 전체를 단일 머신에서 처리할 수 있지만, 대규모 데이터셋의 경우 하나의 머신으로는 저장 및 계산이 어려워 여러 파티션으로 분산 저장하게 됩니다. 이러한 파티션 단위를 OpenSearch에서는 '샤드'라고 부릅니다.
샤드는 저장 단위이자 계산 단위로 작동하며, OpenSearch Service 클러스터에서는 이 샤드를 여러 노드에 분산하여 병렬처리를 극대화합니다. 인덱싱 또는 질의 처리 시 각각의 샤드는 독립적으로 작동하며, 그 결과를 모아서 최종 응답을 구성합니다.
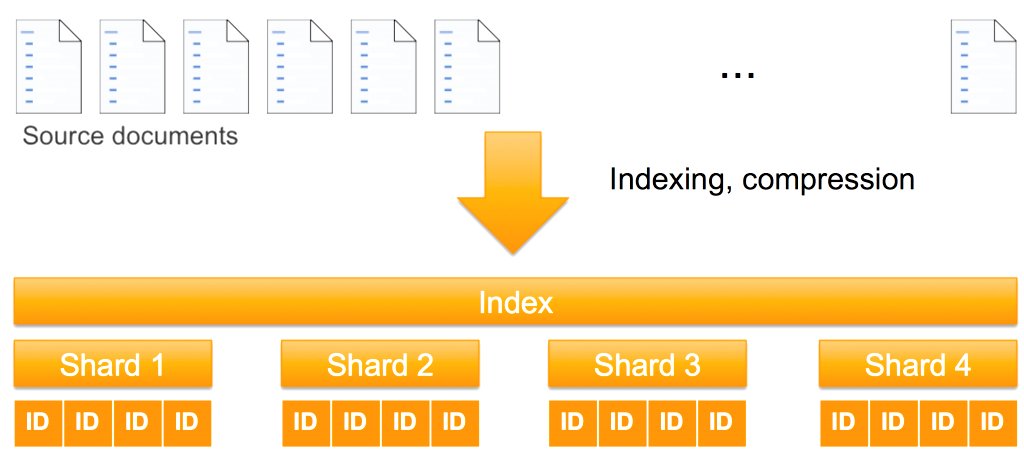
프라이머리 샤드와 리플리카 샤드의 차이
OpenSearch 인덱스는 두 가지 샤드를 포함합니다. 프라이머리 샤드(primary shard)는 기본 데이터가 저장되는 곳이고, 리플리카 샤드(replica shard)는 프라이머리 샤드의 사본 역할을 합니다. 예를 들어, 5개의 프라이머리 샤드와 1개의 리플리카를 설정하면 총 10개의 샤드를 사용하게 됩니다.
프라이머리 샤드에 쓰기 작업이 먼저 전달되고, 이후 리플리카 샤드로 복제됩니다. 이는 장애 발생 시 데이터 유실을 방지하고, 고가용성을 보장합니다. 다음 구조는 프라이머리와 리플리카 샤드가 어떻게 분산되는지를 보여줍니다.
워크로드에 따른 샤드 수 가이드
- 검색 워크로드 (검색 애플리케이션용)
- 저장 기준: 총 데이터 크기를 30GB로 나눠서 샤드 수 정의
- 샤드 크기 최소 10GB 가능: 응답 속도 향상이 필요한 경우 작은 샤드로 분할
- 적중 횟수가 많을수록 샤드 수 증가 ⇒ 병렬 처리 증가
- 로그 분석 (로그 수집 및 분석용)
- 저장 기준: 1일 또는 1개월 단위 인덱스를 50GB 기준으로 분할
- ISM 롤오버 정책 사용 권장 (min_size=50GB 설정)
- 적중 횟수가 적은 경우 큰 샤드 사용 / 질의량 많으면 분할 처리 권장
- 벡터 데이터베이스 (k-NN, 임베딩 벡터 검색)
- 저장 기준: 50GB 기준으로 샤드 수 계산
- 질의 특성에 따라 샤드 크기 조절 (예: 하이브리드 질의는 작은 샤드, 순수 벡터 질의는 큰 샤드 사용)
- OpenSearch는 디스크 기반 검색, 벡터 양자화 등의 최적화 기법도 지원
샤드는 작을수록 무조건 좋은가?
데이터가 기준 샤드 크기(검색: 30GB, 로그/벡터: 50GB)보다 작으면 단일 샤드를 사용하는 것이 오히려 성능에 유리할 수 있습니다. 너무 많은 샤드가 있으면 질의 분산 및 집계 오버헤드가 커져서 반대로 성능 저하가 발생할 수 있습니다. 따라서 소규모 데이터셋의 경우 샤드 수를 늘리는 것보다 단일 프라이머리 샤드를 고려해보는 것이 좋습니다.
샤드 수 설정 방법 및 자동화
샤드 수는 인덱스 생성 시에만 설정할 수 있습니다. 설정 후에는 동적으로 조정할 수 없으므로 초기 설계가 중요합니다. 다음은 OpenSearch에서 API를 활용해 샤드 수를 설정하는 예시입니다.
단일 인덱스 생성 시:
curl -XPUT https://<도메인엔드포인트>/<인덱스명> -H 'Content-Type: application/json' -d '
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}'
롤링 인덱스를 사용하는 경우(자동화 예):
curl -XPUT https://<도메인엔드포인트>/_index_template/<템플릿명> -H 'Content-Type: application/json' -d '
{
"index_patterns": ["logs*"],
"template": {
"settings": {
"index" : {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
}'
결론
OpenSearch Service에서 샤드 구조 설정은 인덱스 성능과 직결되는 핵심 요소입니다. 한번 설정하면 변경이 불가능한 전제 아래, 워크로드 특성에 맞는 최적의 샤드 전략을 컴파일하는 것이 매우 중요합니다. 검색, 로그 분석, 벡터 검색 등 워크로드별 최적화된 가이드를 활용하여 더욱 효율적인 OpenSearch 환경을 구축해보세요. 보다 구체적인 전략은 OpenSearch 공식 문서나 성능 모범 사례 문서를 참조하면 더욱 정밀한 튜닝이 가능합니다.
https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-101-how-many-shards-do-i-need/
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
