Apache Spark 디버깅을 AI로 자동화하는 방법 – Spark History Server MCP 소개
현대 데이터 파이프라인은 갈수록 대규모화되고 있으며, 이를 처리하는 핵심 기술로 Apache Spark가 널리 사용되고 있습니다. 하지만 Spark의 대규모 분산 처리 구조는 복잡한 구성과 성능 이슈 해결 측면에서 많은 시간과 전문 지식을 요구합니다. 특히, Spark에서 ETL 파이프라인 실패나 지연 시 그 원인을 파악하려면 로그, UI, 모니터링 툴 등 다양한 인터페이스를 오가며 수동으로 진단해야 했습니다.
이러한 한계를 해결하고자 AWS에서는 Apache Spark History Server 데이터를 AI 기반으로 분석하고 디버깅할 수 있는 MCP(Server) 기능을 오픈소스로 제공하기 시작했습니다. 이 글에서는 Spark 디버깅의 자동화를 가능하게 해주는 MCP 서버에 대해 살펴보고, 실제 활용 사례와 배포 가이드를 소개합니다.
복잡한 Spark 관찰성과 디버깅 문제
아래는 Apache Spark 사용자들이 흔히 겪는 문제들입니다:
- 다양한 Spark 리소스와의 복잡한 구성 – 잘못되거나 비효율적인 설정은 성능 저하나 오류의 원인이 되며, 원인 분석 자체도 어렵습니다.
- 메모리 기반 처리 구조 – 각 워커의 리소스가 파편화되어 병목 구간을 쉽게 확인하기 어렵습니다.
- Lazy Evaluation 처리 방식 – 실행 계획이 복잡하고 로그 상의 연관성이 명확하지 않아 디버깅에 시간과 노력이 많이 듭니다.
Spark History Server는 작업 히스토리와 실행 타임라인, 리소스 사용량, SQL 실행 계획 등을 제공하지만, 이를 해석해 최적화 인사이트를 얻기 위해선 높은 수준의 내부 구조 이해가 필요합니다.
MCP 서버가 바꾸는 Spark 디버깅 환경
MCP(Model Context Protocol)는 AI 에이전트가 특정 시스템의 데이터를 구조화된 형태로 접근할 수 있게 해주는 표준 인터페이스입니다. Spark History Server용 MCP는 기존의 복잡했던 Spark 디버깅 환경을 AI 기반의 자연어 분석 구조로 전환시켜줍니다.
즉, 기존처럼 UI를 탐색하지 않아도 자연어로 "spark-abcd 잡이 왜 실패했는가?"라고 묻는 것만으로도 AI가 로그, 실행 시간, 리소스 소비 내역 등을 종합 분석해 근본 원인을 알려줍니다. 설정 변경 없이 기존 서버에 연결만 하면 되기 때문에 도입도 간편합니다.
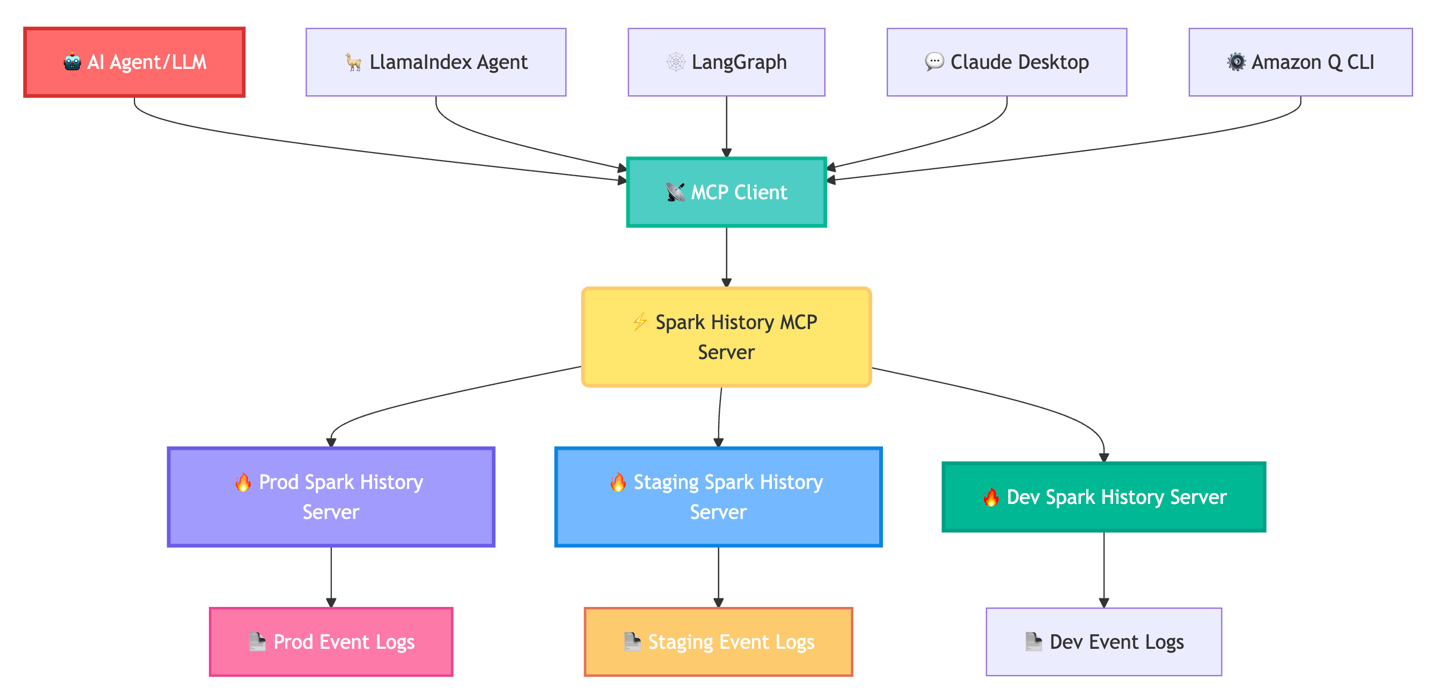
Spark Data 접근의 자동화 – MCP 활용 방법
MCP는 다양한 AI 에이전트와 통합 가능합니다. 기존의 로그 분석과 표준 리포트 외에도 다음과 같은 도구와 연계됩니다:
- Amazon Q Developer CLI
- Claude Desktop
- LlamaIndex
- Strands Agents
- LangGraph
이 도구들은 애플리케이션별, 잡/스테이지/태스크별 지표 분석, SQL 실행 계획 기반 최적화까지 광범위한 성능 분석을 지원합니다.
또한 MCP 서버는 다음과 같은 두 가지 프로토콜을 통해 통신합니다:
- Streamable HTTP: 고급 기능 활성화 목적(LangGraph 등과의 통합)
- STDIO: Claude Desktop, Amazon Q CLI 연동에 최적화
MCP 서버 로컬 설치 가이드
빠르게 테스트를 시작하고 싶은 경우, GitHub에 공개된 리포지토리를 통해 로컬 환경에서 실행할 수 있습니다:
- Git으로 리포지토리를 클론
- 필요한 의존성 설치 (task 사용)
- 샘플 Spark History, MCP 서버, MCP Inspector 실행
- task 명령어로 컨트롤 및 종료
이 과정은 맥에서도 가능하며, 전체 커맨드는 프로젝트 README에 자세히 나와 있습니다.
AWS Glue 및 Amazon EMR과의 통합
MCP 서버는 자가 호스팅 Spark 환경뿐 아니라 AWS Glue, Amazon EMR과도 직접 연동됩니다. 다음은 주요 활용 시나리오입니다:
- AWS Glue: EC2에 설치된 Spark History Server와 연동하거나 Docker로 로컬 실행할 수 있으며, 다양한 활용 가이드가 포함된 예제가 제공됩니다.
- Amazon EMR: Persistent Spark UI 기능과 연동해 클러스터 ARN을 통해 자동 연결되고, 보안 토큰 기반 인증으로 세밀한 데이터 접근이 가능합니다.
해당 통합 구조를 활용하면 "spark-
향후 발전 방향
Spark History Server MCP는 Apache 2.0 기반의 오픈소스로 누구나 기여하고 배포할 수 있습니다. 향후 AWS Glue, Amazon EMR과의 통합 심화는 물론 신규 분석 툴과 자연어 처리 모델과의 연계도 기대할 수 있습니다.
Spark 사용자는 더 이상 UI를 넘나들며 디버깅에 수 시간 또는 수 일을 보낼 필요 없이, AI 기반 성능 분석과 최적화 제안을 바로 활용할 수 있습니다.
오늘부터 바로 시작해보세요
- GitHub 저장소 살펴보기: https://github.com/DeepDiagnostix-AI/mcp-apache-spark-history-server
- 다양한 사용 예시와 배포 가이드 확인
- 커뮤니티 참여 및 Feature 기여
- 기업 내 구축 또는 POC 테스트 수행
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
