기업 데이터 검색 고도화를 위한 방법: Amazon RDS와 Amazon Aurora에서 OpenSearch로 실시간 연동하기
효율적인 검색 환경 구축은 디지털 시대의 경쟁력을 결정짓는 핵심 요소 중 하나입니다. 특히 다양한 구조화 데이터를 저장한 관계형 데이터베이스(RDB)는 정교한 비즈니스 로직에 강점을 보이지만, 대용량 비정형 텍스트에 대한 검색 성능과 자동화 활용 측면에서는 한계를 보이곤 합니다. 이러한 한계 해결의 방법으로 최근 AWS는 Amazon RDS/Aurora와 Amazon OpenSearch Service 간 연동을 공식적으로 지원하며 데이터 검색 환경의 혁신을 실현했습니다.
이 글에서는 관계형 데이터베이스(RDS, Aurora)의 데이터를 Amazon OpenSearch Service와 실시간 동기화하여 검색 및 분석 역량을 강화하는 활용 방안을 설명하고, 구성 사례와 함께 배포 가이드를 소개합니다.
효율성과 성능을 모두 확보하는 OpenSearch Ingestion 디플로이먼트 가이드
Amazon OpenSearch Service는 모든 필드를 색인하고, 즉시 쿼리할 수 있는 능력을 바탕으로 고성능 검색 기능(예: 하이브리드 검색, 유사도 순위, 파셋 검색 등)을 지원합니다. 이런 장점을 RDS, Aurora 같은 관계형 데이터와 결합하기 위해선 기존에는 복잡한 ETL 파이프라인 구축이 필요했지만, OpenSearch Ingestion을 활용하면 이러한 과정을 자동화하고 실시간으로 동기화할 수 있습니다.
활용 가능한 데이터베이스는 다음과 같습니다:
- Amazon Aurora MySQL-Compatible Edition (v8.0 이상)
- Amazon RDS for MySQL (v8.0 이상)
- Amazon Aurora PostgreSQL-Compatible Edition (v16 이상)
- Amazon RDS for PostgreSQL (v16 이상)
자동화된 데이터 동기화는 다음 아키텍처를 따릅니다:
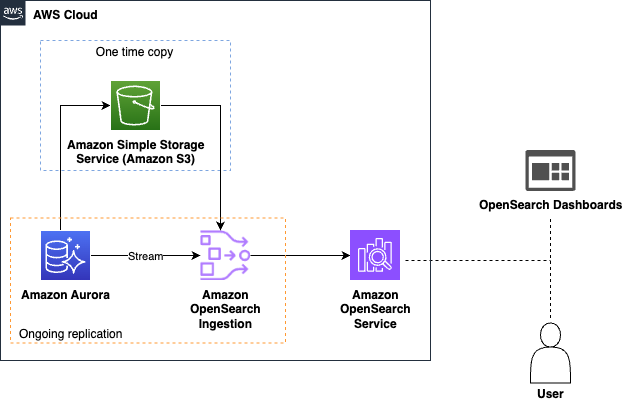
- Amazon Aurora 또는 RDS에서 DB 데이터를 S3로 내보낸 후, 해당 스냅샷을 OpenSearch Ingestion이 읽어들입니다.
- 그 후 데이터 변경 스트림(CDC)을 감지하여, 변경 사항을 실시간으로 OpenSearch에 반영합니다.
- 이 과정을 통해 사용자는 복잡한 파이프라인 구성 없이 검색 인덱스를 최신 상태로 유지할 수 있습니다.
OpenSearch 내부에서는 매핑 기능을 통해 데이터 타입을 자동으로 변환하며, 특히 DATE/Numeric/Text 필드는 적절히 일치하는 OpenSearch 필드 유형으로 자동 매핑됩니다.
복잡한 관계형 구조를 검색 최적화 구조로 전환
아래의 샘플 HR 데이터베이스 사례에서는 다양한 테이블 데이터를 조인하고, denormalized 형태로 구성된 employee_details 뷰를 통해 단일 검색 문서로 구성하는 방법을 보여줍니다.
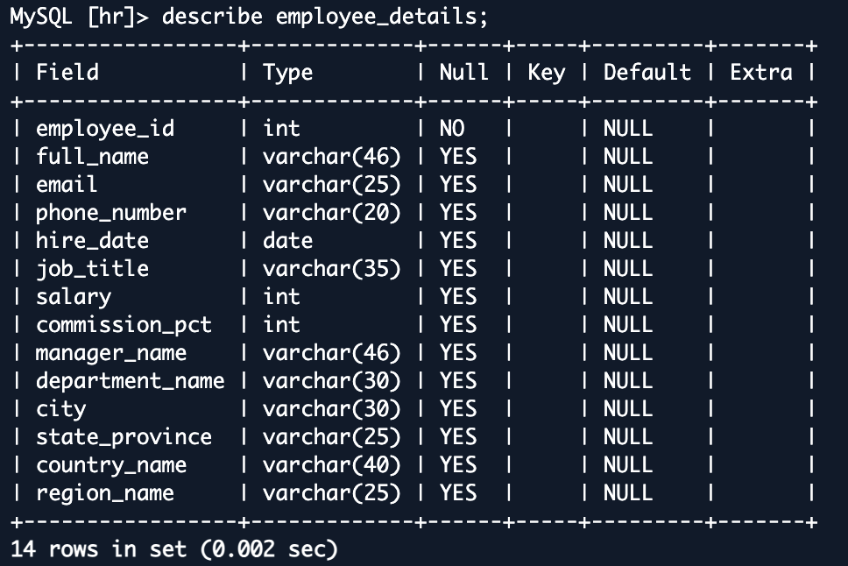
이렇게 생성된 합성 데이터는 OpenSearch 인덱스에 저장되어, 부서+지역 검색이나 급여 분포 분석과 같은 고급 쿼리를 제공할 수 있습니다. 이는 전통적인 정규화된 RDS 환경보다 높은 쿼리 속도와 효율성을 가져다줍니다.
실시간 정합성을 유지하는 자동화된 파이프라인 구성
OpenSearch Ingestion 파이프라인 구성 예시는 다음과 같습니다:
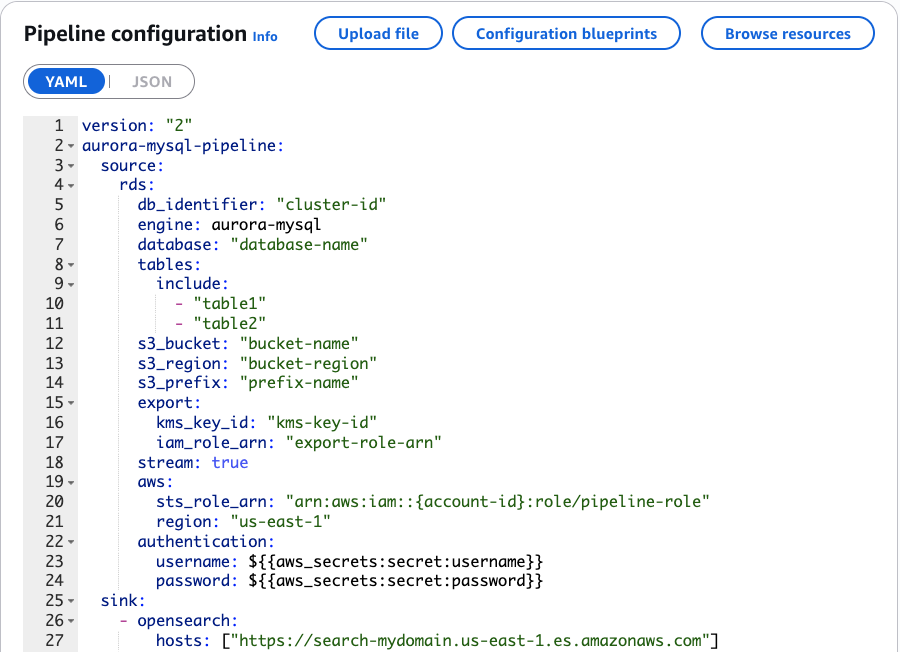
해당 파이프라인은 소스 테이블(예: employees, departments 등)에 대한 변경을 추적하며, OpenSearch 인덱스에 실시간 반영합니다. 관리자는 AWS CloudWatch를 통해 파이프라인 상태 및 처리량을 모니터링할 수 있습니다.
성능 실증: DB 반영 후 즉시 검색 가능한 구조
예를 들어, 다음과 같이 직원의 급여를 업데이트하면:
UPDATE hr.employees SET SALARY = 26000 WHERE EMPLOYEE_ID = 100;
그 즉시 OpenSearch 내 직원 문서에도 해당 급여 정보가 반영됩니다:

이러한 실시간성과 검색 활용성을 통해, 사용자는 재고 변화 감지, 검색 결과 개인화, 추천 시스템 등의 고수준 기능을 빠르게 구현할 수 있습니다.
활용 시 주의사항 및 비교 포인트 정리
- 동일 리전 및 동일 계정 내에서만 지원
- 기본키(PK) 필드 존재 필수
- DDL 명령은 반영되지 않음
- 검색 인덱스 자동 생성 가능 (커스터마이징도 가능)
결론
Amazon RDS 또는 Aurora와 OpenSearch Service의 통합은 실시간 동기화와 강력한 검색 기능을 동시에 확보할 수 있는 이상적인 아키텍처입니다. 복잡한 ETL 자동화 없이 운영 비용을 절감하고, 사용자 경험에 집중할 수 있는 환경을 제공합니다. 다양한 검색 기반 애플리케이션, 리포팅, 로그 분석 등에 이상적인 선택이며, 현대적 데이터 설계에 유리한 활용 방법입니다.
다양한 활용 가능한 방법과 설정은 AWS 공식 문서에서 자세히 확인할 수 있습니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
