아파치 아이스버그 Iceberg 테이블에서 Avro, ORC 포맷 자동 컴팩션 자동화 활용 가이드
최근 빅데이터 분석 환경에서 중요하게 떠오르는 과제 중 하나는 대규모 데이터의 안정적인 관리와 고성능 분석을 동시에 충족하는 것입니다. 특히 Amazon S3 상에 구축된 Apache Iceberg 기반의 데이터 레이크하우스 구조에서는 다양한 파일 포맷을 다루며 이를 최적화된 방식으로 유지해야 합니다. 이번 블로그에서는 Amazon S3 Tables를 활용하여 Iceberg 테이블에서 Avro 및 ORC 포맷에 대한 자동 컴팩션 지원 기능을 소개하고, 실제 활용 예시 및 성능 개선 효과에 대해 다룹니다.
Iceberg 테이블과 자동 컴팩션 개요
Apache Iceberg는 확장 가능하면서도 오픈 포맷을 기반으로 다양한 분석 엔진과 호환 가능한 테이블 포맷입니다. Iceberg는 Amazon Athena, Apache Spark, Flink, Trino 등의 분석 엔진과 통합되어, 데이터 레이크 환경에서 SQL 기반의 고성능 데이터 분석을 가능케 합니다. 하지만 Iceberg 테이블은 고속의 실시간 스트리밍 처리, 소형 파일 과다 현상 방지, 데이터 정합성 유지 등을 위해 지속적인 컴팩션(Compaction)이 필요합니다.
Amazon S3 Tables는 2024년 AWS 리인벤트 행사를 통해 최초로 Parquet 기반 Iceberg 테이블의 기본 지원을 공개했으며, 최근에는 Avro, ORC 같은 추가 포맷에 대해 자동 컴팩션을 적용할 수 있는 기능을 새롭게 도입했습니다. 이러한 자동화는 Amazon SageMaker에서 구축된 일반 S3 Bucket 기반 테이블 환경에서도 Glue Data Catalog를 통해 동일하게 구현할 수 있습니다.
세 가지 주요 파일 포맷 비교
Iceberg는 세 가지 대표적인 파일 포맷 – Parquet, ORC, Avro – 모두를 지원합니다. 이를 통해 다양한 유스케이스에 따라 최적의 포맷을 선택하고 활용할 수 있는 유연성을 제공합니다.
- Parquet: 열 기반 포맷으로, 복잡하고 중첩된 데이터 분석에 적합하며, 폭넓은 도구 호환성과 우수한 쿼리 성능을 제공합니다.
- ORC: Hive 중심의 대용량 배치 처리를 위해 설계되었으며, 뛰어난 압축률과 경량 인덱스를 통해 Hive 환경에서 매우 빠른 필터링 속도를 제공합니다.
- Avro: Kafka 등 스트리밍 시스템과 연동이 용이한 행 기반 포맷이며, 스키마 진화(scheme evolution)을 저장소에 내장하여 실시간 데이터 적재 및 처리에 적합합니다.
자동 컴팩션 vs 비컴팩션 성능 비교 사례
IoT 시나리오를 가정한 데이터 적재 환경에서 총 200억 건 이상의 이벤트를 처리하며, Iceberg 테이블에 데이터를 MERGE INTO 방식으로 저장한 후 Amazon Athena로 쿼리를 실행하여 성능을 측정했습니다.
- 테스트 대상은 Avro/ORC 포맷별로 자동 컴팩션을 적용한 테이블과 아닌 테이블 두 가지.
- Merge-on-read 방식을 사용한 델타 ingestion 구성.
- 평균 Row 수 20억 개 이상 기반의 세 가지 쿼리를 반복 실행.
- 결과적으로 컴팩션이 적용된 테이블은 최대 39.98%의 쿼리 성능 향상 효과를 보였습니다.
Query 1: Avro – 15.41% 향상 / ORC – 32.63% 향상
Query 2: Avro – 12.20% 향상 / ORC – 39.98% 향상
Query 3: Avro – 27.29% 향상 / ORC – 14.11% 향상
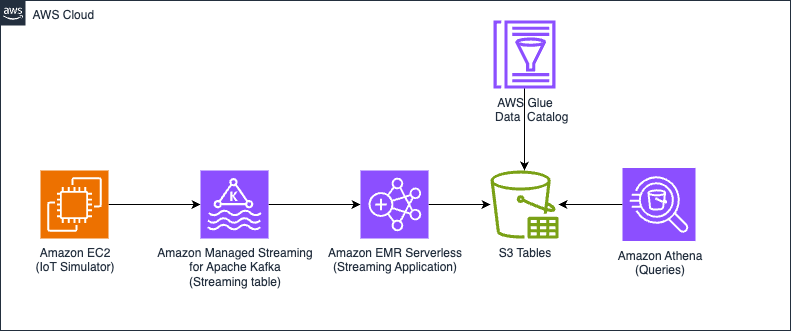
배포 및 구성 가이드 개요
실제 환경에서 이 기능을 평가 및 구현하기 위해 필요한 AWS 리소스는 다음과 같습니다.
- Amazon S3 Tables 또는 일반 S3 버킷
- AWS Glue 및 Lake Formation 구성
- EMR Serverless 애플리케이션, Kafka(MSK) 클러스터
- Java 기반 EC2 데이터 프로듀서 및 Apache Kafka 환경
- Iceberg ingestion을 위한 체크포인트 분리 디렉토리 구성 (/checkpointAvro, /checkpointORC 등)
또한, Spark Streaming 기반 ingestion 애플리케이션을 4개 테이블(Avro/ORC 각 컴팩션, 비컴팩션) 각각에 대해 실행하고, Kafka를 통해 데이터를 실시간 전송하여 성능을 비교 측정합니다.
활용 시 고려사항 및 자동화 장점
Iceberg 테이블 자동 컴팩션은 다음 상황에서 큰 효과를 발휘합니다.
- 다량의 실시간 데이터가 스트리밍으로 지속 유입되는 경우
- 소형 파일 다수 생성으로 인한 Athena/Presto 성능 저하 상황
- 데이터 컬럼 추가 등 스키마 진화가 빈번한 환경
자동 컴팩션이 제공하는 주요 장점은 다음과 같습니다.
- Amazon S3 Tables에서는 snapshot 보존과 파일 삭제도 자동화
- Glue Data Catalog 및 SageMaker 기반 아키텍처에서도 동일한 유지 관리 제공
- 쿼리 성능 향상 → 비용 절감 → 운영 자동화 효과
결론
Amazon S3 Tables 및 Amazon S3 일반 버킷 기반 Lakehouse 아키텍처에서도 이제 Iceberg 테이블의 Parquet 뿐만 아니라 Avro, ORC 포맷에 대한 자동 컴팩션이 지원됩니다. 다양한 분석 환경과 파일 포맷에 걸쳐 쿼리 성능을 향상시키고 운영 효율을 극대화할 수 있도록 돕는 이 기능은 향후 데이터 웨어하우스와 데이터 레이크 통합을 위한 핵심 기술로 자리매김할 것입니다. AWS Glue 기반 옵티마이저 또는 S3 Tables 자동화를 통해, 귀사의 데이터 레이크 프로젝트에 적합한 구조를 선택해보시길 바랍니다.
AI, Cloud 관련한 문의는 아래 연락처로 연락주세요!
(주)에이클라우드
이메일 : acloud@a-cloud.co.kr
회사 번호 : 02-538-3988
회사 홈페이지 : https://www.a-cloud.co.kr/
문의하기
